Ray-Core设计原理与理解
从部署到使用的实操记录
Some Docs
上一篇文章我们大概讲了一下什么是RAY,他和spark的区别是什么,以及可以用来做什么。这篇文章让我们进一步研究ray,如何部署,如何使用,它又是如何运行的。
What’s Ray
首先基因很重要,所以我们先需要探查下Ray最初是为了解决什么问题而产生的。
Ray的论文显示,它最早是为了解决增强学习的挑战而设计的。增强学习的难点在于它是一个需要边学习,边做实时做预测的应用场景,这意味会有不同类型的tasks同时运行,并且他们之间存在复杂的依赖关系,tasks会在运行时动态产生产生新的tasks,现有的一些计算模型肯定是没办法解决的。
如果Ray只是为了解决RL事情可能没有那么复杂,但是作者希望它不仅仅能跑增强学习相关的,希望是一个通用的分布式机器学习框架,这就意味着Ray必然要进行分层抽象了,也就是至少要分成系统层和应用层。
系统层面
既然是分布式的应用,那么肯定需要有一个应用内的resource/task调度和管理。
首先是Yarn,K8s等资源调度框架是应用程序级别的的调度,Ray作为一个为了解决具体业务问题的应用,应该要跑在他们上面而不是取代他们,而像Spark/Flink虽然也是基于task级别的资源调度框架,但是因为他们在设计的时候是为了解决一个比较具体的抽象问题,所以系统对task/资源都做了比较高的封装,一般用户是面向业务编程,很难直接操控task以及对应的resource。
我们以Spark为例,用户定义好了数据处理逻辑,至于如何将这些逻辑分成多少个Job,Stage,Task,最后占用多少Resource(CPU,GPU,Memory,Disk) 等等,都是由框架自行决定,而用户无法染指。这也是我一直诟病Spark的地方。所以Ray在系统层面,是一个通用的以task为调度级别的,同时可以针对每个task控制资源粒度的一个通用的分布式task执行系统。
记住,在Ray里,你需要明确定义Task以及Task的依赖,并且为每个task指定合适(数量,资源类型)的资源。比如你需要用三个task处理一份数据,那么你就需要自己启动三个task,并且指定这些task需要的资源(GPU,CPU)以及数量(可以是小数或者整数)。
而在Spark,Flink里这是不大可能的。Ray为了让我们做这些事情,默认提供了Python的语言接口,你可以像使用Numpy那样去使用Ray。实际上,也已经有基于Ray做Backend的numpy实现了,当然它属于应用层面的东西了。
Ray系统层面很简单,也是典型的master-worker模式。类似spark的driver-executor模式,不同的是,Ray的worker类似yarn的worker,是负责Resource管理的,具体任务它会启动Python worker去执行你的代码,而spark的executor虽然也会启动Python worker执行python代码,但是对应的executor也执行业务逻辑,和python worker有数据交换和传输。
应用层面
你可以基于Ray的系统进行编程,因为Ray默认提供了Python的编程接口,所以你可以自己实现增强学习库(RLLib),也可以整合已有的算法框架,比如tensorflow,让tensorflow成为Ray上的一个应用,并且轻松实现分布式。
我记得知乎上有人说Ray其实就是一个Python的分布式RPC框架,这么说是对的,但是显然会有误导,因为这很可能让人以为他只是“Python分布式RPC框架”。
How to use
部署
首先无论是本机部署还是集群部署都需要下载相应的ray-driver,可以理解为一个客户端工具
https://docs.ray.io/en/latest/ray-overview/installation.html
本机部署
使用pip install完整版时,已经下载好了完整的ray服务套件
Docker部署
https://hub.docker.com/r/rayproject/ray
使用命令启动
1
docker run --shm-size=<shm-size> -t -i --gpus all rayproject/ray:<ray-version>-gpu
k8s部署
使用官方kuberay-chart进行部署安装,该模块会安装operator进行管理Ray-cluster,这也是官方推荐的方式
https://docs.ray.io/en/latest/cluster/kubernetes/index.html
RayCluster: KubeRay 完全管理 RayCluster 的生命周期,包括集群创建/删除、自动扩展和确保容错。
RayJob: 通过 RayJob,KubeRay 自动创建 RayCluster,并在集群准备就绪时提交作业。您还可以将 RayJob 配置为在作业完成后自动删除 RayCluster。
RayService: RayService 由两部分组成:RayCluster 和 Ray Serve 部署图。 RayService 为 RayCluster 和高可用性提供零停机升级。
安装Operator
1
2
3
4
5
6
7
8
9
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
# Install both CRDs and KubeRay operator v0.6.0.
helm install kuberay-operator kuberay/kuberay-operator --version 0.6.0
# Check the KubeRay operator Pod in `default` namespace
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# kuberay-operator-6fcbb94f64-mbfnr 1/1 Running 0 17s
- 安装Ray-cluster
1
2
3
4
5
6
7
8
# Deploy a sample RayCluster CR from the KubeRay Helm chart repo:
helm install raycluster kuberay/ray-cluster --version 0.5.0
# Once the RayCluster CR has been created, you can view it by running:
kubectl get rayclusters
# NAME DESIRED WORKERS AVAILABLE WORKERS STATUS AGE
# raycluster-kuberay 1 1 ready 72s
为了实现更详细化的定制,将helmchart下载到本地,修改values等文件
helm get all kuberay/ray-cluster
因需要将服务部署到私有集群中,需要对一些配置进行修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# ... some yaml code
imagePullSecrets:
- name: an-existing-secret
# ... some yaml code
head:
tolerations: [{"key": "value"}] # head调度配置
# ... some yaml code
worker:
tolerations: [{"key": "value2"}] # worker调度配置
containerEnv:
- name: RAY_memory_monitor_refresh_ms
value: "0" # 因调度时出现大量超内存直接杀死worker,主动关闭内存监控自动清理
# ... some yaml code
部署服务 helm install -f ray-cluster/values.yaml raycluster ./ray-cluster
cluster.yaml 详细配置要点
https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/config.html
rayVersion配置ray下载的版本,本文在编写的时候用的2.5.1,当时2.6.1已经出现要在集群中分发自定义代码依赖项,您可以构建自定义容器镜像。
【注意】在任何情况下,请确保您的 CR 中的所有 Ray 镜像都具有相同的 Ray 版本和 Python 版本。
head.rayStartParams设置ray启动时候的参数为 Ray head pod 设置
num-cpus:"0"将阻止在头上调度具有非零 CPU 要求的 Ray 工作负载。resources 定义资源名称,这样能在调用时候使用相关资源:
@ray.remote(resources={"Custom2": 1})
workerGroupSpec.minReplicasworkerGroupSpec.maxReplicas用于自动缩放配置Ray pod 模板还可以指定额外的 sidecar 容器,用于日志处理等目的。
resources设置资源大小,最理想的方案是将pod的大小设置为整个node节点的大小,少量的大Pod效率更高:更有效地使用每个 Ray pod 的共享内存对象存储
减少 Ray pod 之间的通信开销
减少每个 pod Ray 控制结构(例如 Raylets)的冗余
【注意】在转发给 Ray 之前,CPU 数量将四舍五入为最接近的整数。
nodeSelector和tolerations控制工作组的 Ray Pod 的调度head service port
Ray Client (default port 10001)
Ray Dashboard (default port 8265)
Ray GCS server (default port 6379)
Ray Serve (default port 8000)
Ray Prometheus metrics (default port 8080)
如果需要将服务暴露到集群外使用,可以使用service+nodeport
自动缩放
使用原生k8s部署Ray
https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/static-ray-cluster-without-kuberay.html
使用命令动态缩放
1
2
3
4
5
6
7
8
9
from ray.autoscaler.sdk import request_resources
# Request 1000 CPUs.
request_resources(num_cpus=1000)
# Request 64 CPUs and also fit a 1-GPU/4-CPU task.
request_resources(
num_cpus=64, bundles=[{"GPU": 1, "CPU": 4}])
# Same as requesting num_cpus=3.
request_resources(
bundles=[{"CPU": 1}, {"CPU": 1}, {"CPU": 1}])
Ray Core
Ray的核心使用非常简单,核心内容分为了三个大类:Tasks,Actors,Object。
除此以外还有Placement Groups和Environment Dependencies
Task
https://docs.ray.io/en/latest/ray-core/tasks.html
task任务本质是以函数为出发点,分发启动异步任务,其中,可以通过remote声明时设置默认资源,也可以在启动时通过options设置资源:
1
2
3
4
5
6
7
8
9
10
11
12
13
import ray
import time
@ray.remote(num_cpus=4, num_gpus=2)
def slow_function():
time.sleep(10)
return 1
# Ray tasks are executed in parallel.
# All computation is performed in the background, driven by Ray's internal event loop.
for _ in range(4):
# This doesn't block.
slow_function.options(num_cpus=3).remote()
remote返回的handler可以传递给下一个remote,进行workflow的调用:
1
2
3
4
5
6
7
8
9
10
11
@ray.remote
def function_with_an_argument(value):
return value + 1
obj_ref1 = my_function.remote()
assert ray.get(obj_ref1) == 1
# You can pass an object ref as an argument to another Ray task.
obj_ref2 = function_with_an_argument.remote(obj_ref1)
assert ray.get(obj_ref2) == 2
ray.wait返回已经完成的任务结果但是不阻塞Multiple returns通过设置num_returns让自定义函数返回值设置为多个,num_returns="dynamic"在ray.get时,会返回迭代器,如果在中间发生异常,前面返回的数据也能正常获取。ray.cancel取消任务Scheduling通过设置资源组remote(resources)进行自定义调度max_retries和retry_exceptions让ray自动进行任务重试
Actors
Ray支持在类级别进行分布式操作。这种方式的好处是能远端进行统计能私有操作处理,又能在driver测进行实时获取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import ray
@ray.remote
class Counter:
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
return self.value
def get_counter(self):
return self.value
# Create an actor from this class.
counter = Counter.remote()
name actor可以在options中设定actor的名称,后续可通过ray.get_actor(name)获取。后续可以通过任何一个任务在集群中检索到。如果句柄引用变为0,则会被回收。namespace定义名称的命名空间,默认为匿名空间。options中支持get_if_exists用于获取or创建这个名称的actoroptions中设置lifetime="detached"可以让任务在driver退出后仍然被检索到。但后续请手动使用
ray.kill删掉不用的actor。也可以让actor被调用进而退出:
ray.actor.exit_actor()
Concurrency for Actors
天生支持async/await并发;
options(max_concurrency=2)可以设定并发启动,但是请注意Python的GIL限制https://docs.ray.io/en/latest/ray-core/actors/async_api.html
- 可以设置并发组,使用不同的并发限制,默认会在默认并发组中
实用类-Actor Pool
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import ray from ray.util import ActorPool @ray.remote class Actor: def double(self, n): return n * 2 a1, a2 = Actor.remote(), Actor.remote() pool = ActorPool([a1, a2]) # pool.map(..) returns a Python generator object ActorPool.map gen = pool.map(lambda a, v: a.double.remote(v), [1, 2, 3, 4]) print(list(gen)) # [2, 4, 6, 8]
Object
ray支持内存共享,共享的对象无法被更改。
1
2
3
4
5
6
7
8
import ray
# Put an object in Ray's object store.
y = 1
object_ref = ray.put(y)
# Get object anywhere
ray.get(object_ref)
可以作为remote的参数进行传递
Ray 可以通过谱系重建自动从对象数据丢失中恢复
使用Plasma object store进行序列化和反序列化
- 每个节点都有自己的对象存储。当数据放入对象存储时,它不会自动广播到其他节点。数据保留在写入器本地,直到另一个节点上的另一个任务或参与者请求为止。
Ray中对象是通过worker,或者通过ray.put进行的,执行这个操作的worker或者driver进程就是这个对象的owner。只要owner保持运行,那么这个对象就一定可以被解析。但是如果owner已经挂掉了,针对这个对象的解析就会失败。因为解析的过程实际上就是一个懒加载的问题。
使用
__reduce__自定义序列化方法Serialization — Ray 2.54.0
https://docs.ray.io/en/latest/ray-core/objects/serialization.html使用
ray.util.inspect_serializability来识别棘手的不可序列化问题用户在使用某些 python3.8 和 3.9 版本时可能会遇到内存泄漏。这是由于 python pickle 模块中的错误造成的。Python 3.8.2rc1、Python 3.9.0 alpha 4 或更高版本已解决此问题。
一旦对象存储已满,会将对象溢出到外部存储。可以通过设置
object_spilling_config定义溢出到的目录;集群模式使用--system-config
环境依赖
python的一些包会在ray的默认包之外,这些包需要进行额外安装:
通过重新封装ray镜像。推荐的方案。一般用于生产或者改动比较少的集群
通过
runtime_env进行设置,可以在ray.init进行job层设置,也可以在函数、类使用@ray.remote进行task层设置pip对于自定义包,可以使用
py_module进行设置。对于单文件,使用
working_dir进行使用。
runtime_env更多详细参数配置:
1
[https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#api-reference](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#api-reference)
每个node都有10GB的默认大小垃圾回收缓存上限,这一点可以设置
RAY_RUNTIME_ENV_<field>_CACHE_SIZE_GB超过大小限制时,未被使用的会被删除driver新的设置会覆盖旧的
working_dir和py_module支持URI,URI需要直接是ZIP文件的链接:HTTPS/S3/GS。通过这种方式,可以用git管理环境变量,甚至CICD
Scheduling
根据
resource设定调度通过策略调度
https://docs.ray.io/en/latest/ray-core/scheduling/index.html#scheduling-strategies
章节详细内容在framework展开
其他概念
Driver: 程序的 root 或者是主程序,一般指放
ray.init的代码的应用。Job: 来自同个 Driver 的 Task 和 Actor 的集合,Driver 和 Job 是 1:1 映射关系。
What’s the framework
Ray使 用了包括分布式引用计数和分布式内存等组件,这些组件增加了体系结构的复杂性,但对性能和可靠性来说是必需的。
Ray 构建在 gRPC 的基础上,并且在许多情况下与 gRPC 直接调用的性能一致。
设计
数据流概览:
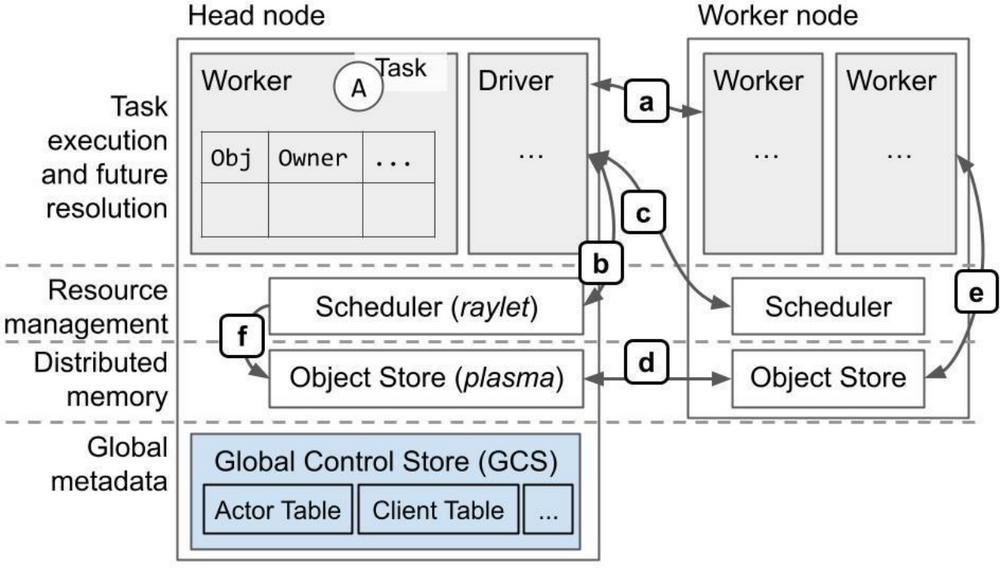
数据流控制概览(大部分通过 gRPC):
a. 任务执行,对象引用计数。
b. 本地资源管理。
c. 远程/分布式资源管理。
d. 分布式对象传输。
e. 大型对象的存储和检索。检索是通过 ray.get 或在任务执行过程中进行。或者用对象的值替换一个任务的ObjectID参数时。
f. 调度器从远程节点获取对象,以满足本地排队任务的依赖满足。
组件
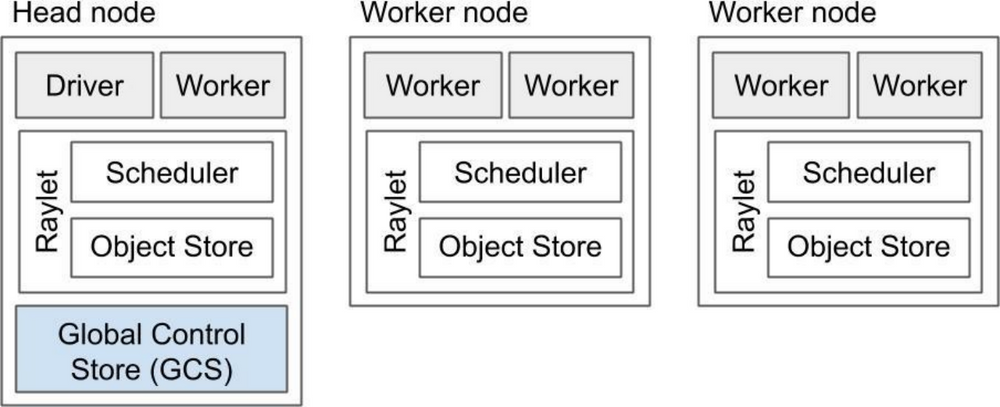
Ray 集群是由一个或者多个 worker 节点组成,每个 worker 节点由以下物理进程组成:
Worker node: 一个或多个的 worker 进程,负责任务的提交和执行,worker 进程要么是无状态的,要么是一个 actor。初始工作线程由机器的 CPU 数量决定。每个工作节点会存储:
一个 ownership 表,worker 引用的对象的系统元数据,例如引用技术和对象位置。
进程内存储,存放一些小对象。
Raylet: 用于管理每个节点上的共享资源,与工作进程不同的是,raylet 是在所有 worker 中共享的:
Scheduler,负责资源管理、任务放置和完成,将 Task 的参数存储在分布式的 Object Store 中。
Object Store,一个共享内存存储,也被称为 Plasma Object Store。负责存储、转移和溢出(spilling,如果 Object Store 满了会移动到外部存储)大型对象。集群中各个 Object Store 共同构建了 Ray 的分布式对象存储。
Head node: 除了有worker和Raylet外还会托管 GCS 和 Driver。包含了自动缩放、任务提交功能
GCS 是一个管理集群的元数据的服务器,比如 actor 的位置、worker 存储的 key-value 对等。GCS in v2容错机制使得它可以运行在任何节点或者多个节点
Dirver 是一个用于指定的用于运行最上级的代码的应用的节点,它能提交任务但是并不能在自己上面执行。虽然 Driver 可以在任何节点上运行,但默认情况下只在 Head 节点运行。一般情况下,会以我们自己的本机作为driver
工作进程与Raylet:
每一个工作进程和 raylet 都被分配了一个唯一的 28-byte 的标识符和一个 ip 地址、端口。
同样的地址和端口在工作进程死亡后重新恢复时可以重复使用,但是唯一 ID 不会。工作进程和 raylet 是 fate-share 的,一个出故障另外一个就无法使用了。
对象生命周期
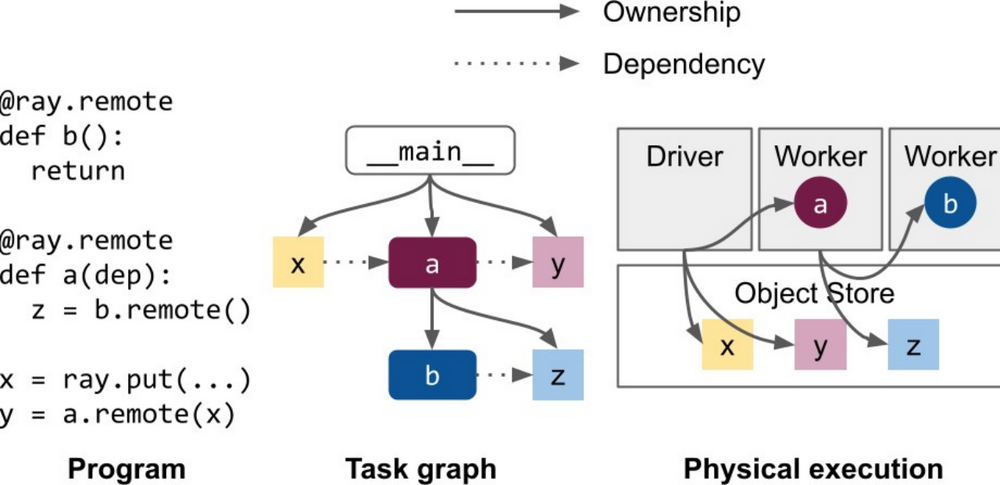
一般有两种方式去创建 ObjectRef,owner 都是实际运行的 worker 的进程:
x_ref = f.remote()
x_ref = ray.put()
v2.0的升级,带来了更好的性能和更简单的结构、提升了可靠性,每个 application 是相对独立的,一个远程调用故障了并不会影响另一个。
但是如果要解析 ObjectRef ,就必须能够访问对象的 owner。并且目前无法转移所有权。
内存模型
关键概念
核心系统
Cluster Orchestrators
Ray 提供了更简单运行在 Kubernetes 的方法,可以使用 KubeRay Operator ,它提供了一种在 k8s 中管理 Ray 集群的解决方案,每个 Ray 集群由一个 head 节点和一群 woker 节点组成。你可以通过 KubeRay 来根据所需调整集群大小,同时也支持 GPU 之类的异构计算,也支持有多个版本的 Ray 的集群。
Parallelization Frameworks
与 multiprocessing 或者 Celery 之类的框架相比,Ray 提供了更通用且性能更高的 API。同时支持内存共享。
Data Processing Frameworks
与 Spark、Flink 等框架相比,Ray 提供的 API 更加底层和灵活,更适合作为 “distributed glue” 框架。另一方面 Ray 没有限定一定是数据处理的模式,而是通过功能库的方式提供不同的处理模式。
Actor Frameworks
不像 Erlang 和 Akka 之类的框架,Ray 支持跨语言的操作和使用那个语言原生的库,能够透明地管理无状态的并行计算,显式地支持 Actor 之间共享内存。
HPC Systems
许多 HPC 系统公开了更低级的消息传递接口,虽然很灵活,但开发人员需要付出更多时间和成本。Ray 上的应用程序可以通过初始化 Ray 的 Actor 组之间的通信群来利用这些优化后的 communication primitives。(类似 allreduce)
2.0 带来的新特性
原本的 Global Control Store 改名叫 Global Control Service,简称 GCS,有着全新的设计更加简单和可靠。
分布式调度器(包括调度策略和置放群组)能让你更方便地扩展功能。
在可靠性和容错性方面进行改进,包括从故障节点中恢复 object reconstruction 和 GCS 的容错机制。
增加了像 KubeRay 等方便集群管理的一些工具。
How does it work
Ray内存使用方式:

系统内存
GCS:用于存储集群中存在的节点和参与者列表的内存。
Raylet:每个节点上运行的C++ raylet进程使用的内存。
应用程序内存
Worker heap:应用程序使用的内存
Object store memory:应用程序通过
ray.put在对象存储中创建对象以及从远程函数返回值时使用的内存。Object store shared memory:应用程序通过
ray.get读取对象时使用的内存。如果节点上已存在对象,则不会导致额外的分配。