项目问题
Go程序CPU过高问题排查
程序因为写法问题导致CPU一致占用,需要排查具体代码
具体步骤
发现问题:使用metrics+Prometheus+grafana的埋点,查看不同服务的资源使用情况进入到Docker/Pod/命令行中,使用top或者htop命令查看进程的资源占用情况。确定具体的程序所在的pid。
通过pid,使用命令
top -d 1 -p <PID> -H查看进程中具体出问题的线程是哪些,进行逐个排查使用dlv工具,具体排查go中哪些协程出了问题:
dlv attach <TID>查看到线程调度的具体是哪个Goroutine_id行中使用
goroutine <gid>查看goroutine的堆栈信息,其中会显示具体的相关代码行由于CPU过高都是因为死循环、递归等问题,所以通过部分的函数名称,可以找到问题
找到具体问题的点,直接去看代码分析问题。
Go程序内存泄漏问题排查
程序会因为各种代码写法,导致一些内存泄漏:
goroutine泄漏以及申请内存后GC没有正常回收
由于内存泄漏的最终结果是被系统kill,因此正常来说不存在首次出现问题时候排查到问题
net/http/pprof提供了一个方法,不使用时不会造成任何影响,遇到问题时可以开启 profiling 帮助我们排查问题。
具体步骤
工具准备:golang的实时内存统计需要用到pprof,这个工具包需要在运行程序时候预装:
1 2 3 4 5 6 7 8
import ( "net/http" _ "net/http/pprof" ) func main() { http.ListenAndServe(":8080", nil) }
在开发机中,或者Docker\Pod的shell中准备好go和pprof工具
请求
http://127.0.0.1:8080/debug/pprof/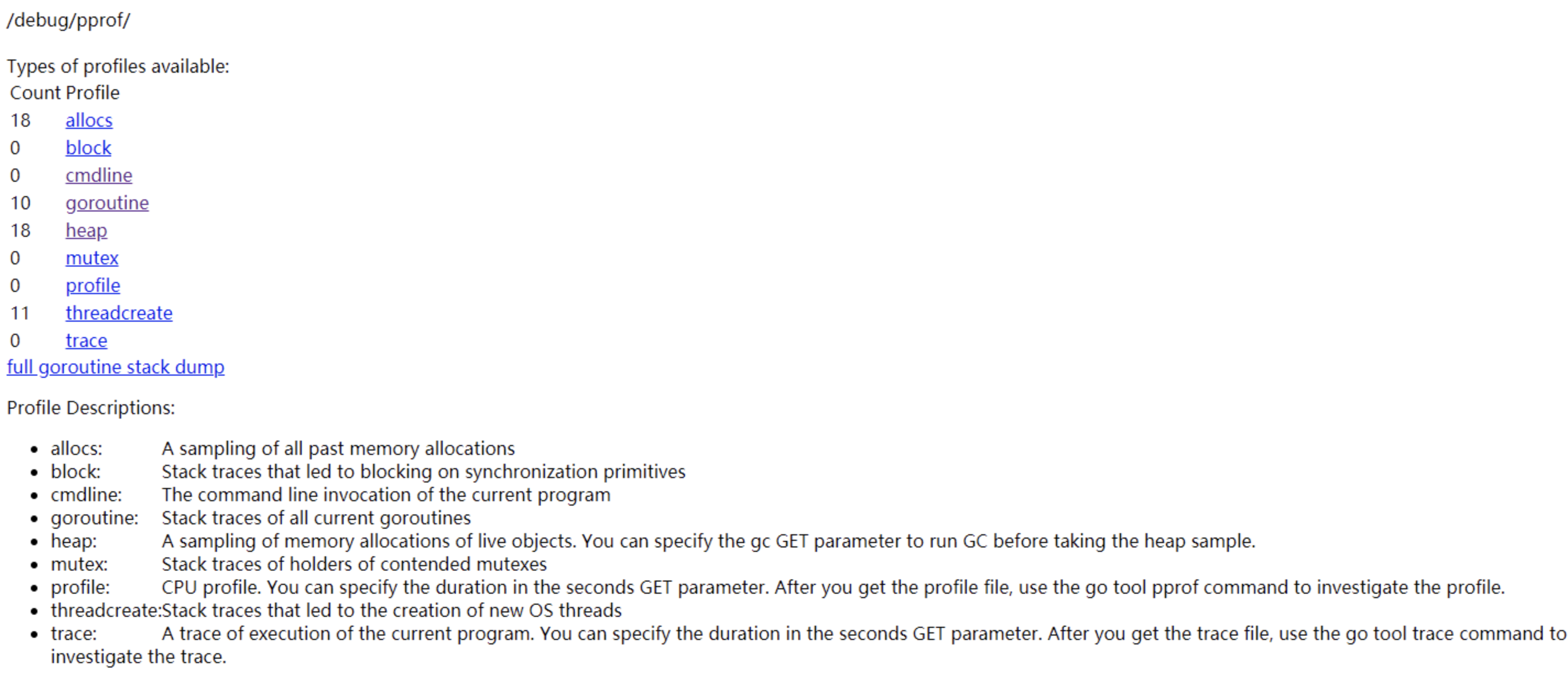
当然生产环境不一定能打开浏览器,可以将profile文件下载下来,到本地运行来获取结果:
1
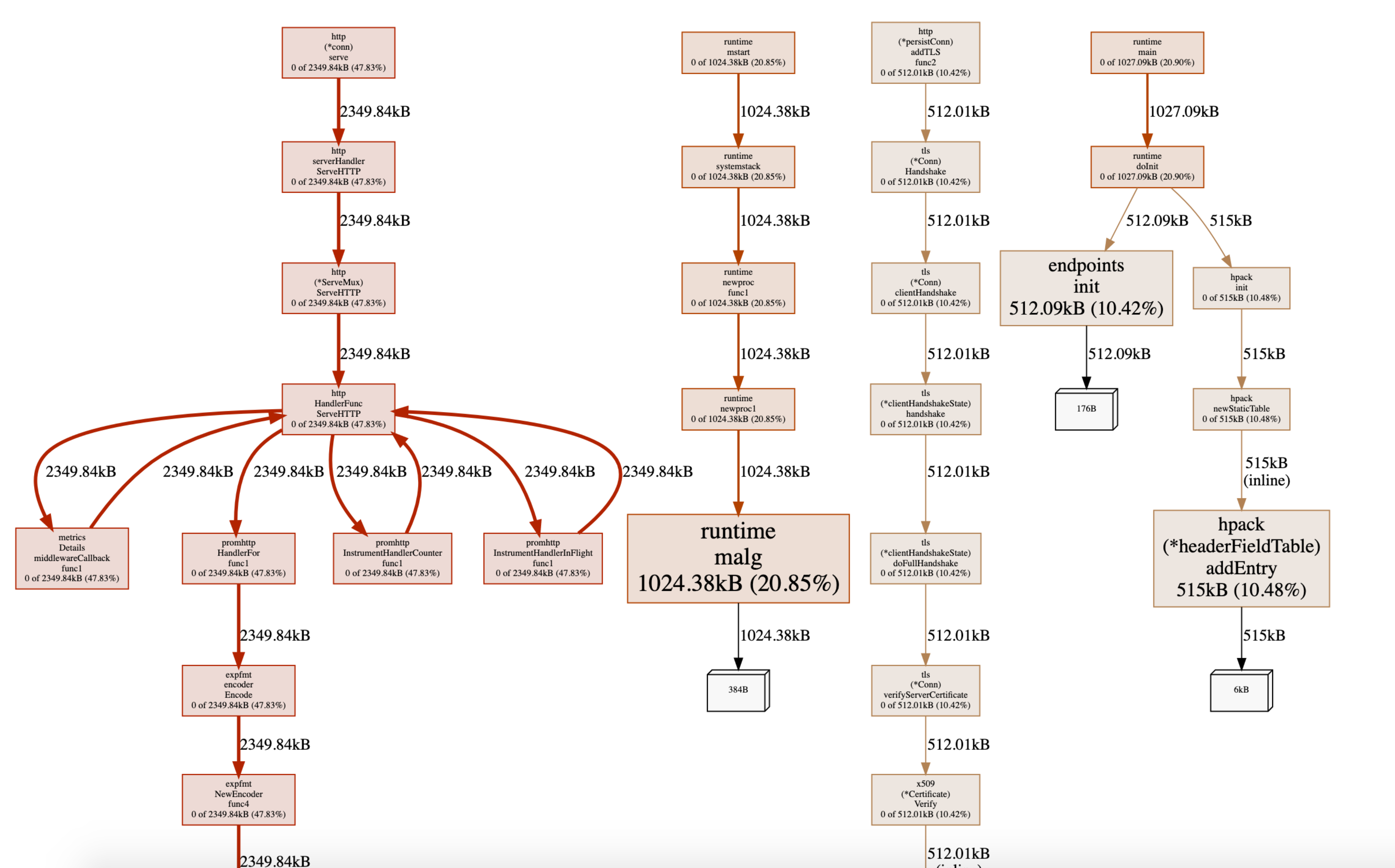
go tool pprof -http :8888 pprof.samples.cpu.001.pb.gz通过pprof的结果进行具体排查代码问题
in_use,收集进程当前仍在使用中的内存
alloc,收集自进程启动后的总的内存分配情况,包括已经释放掉的内存
示列:
bufio.Scanner: token too long
bufio的scanner有默认的64KB的限制,单行长度不可超过。如有需求,可以自定义缓冲区大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package main
import (
"bufio"
"bytes"
"fmt"
)
func main() {
// 模拟的大数据输入,超出默认的 64KB 大小
largeInput := make([]byte, 65536) // 大约 64KB 数据
for i := range largeInput {
largeInput[i] = 'a'
}
largeInput[len(largeInput)-1] = '\n' // 确保有换行符作为分隔
scanner := bufio.NewScanner(bytes.NewReader(largeInput))
// 分配一个更大的缓冲区
buffer := make([]byte, 100000) // 100KB 缓冲区
scanner.Buffer(buffer, len(buffer))
for scanner.Scan() {
fmt.Println("成功读取数据:", len(scanner.Bytes()))
}
if err := scanner.Err(); err != nil {
fmt.Println("读取错误:", err)
}
}