Mysql
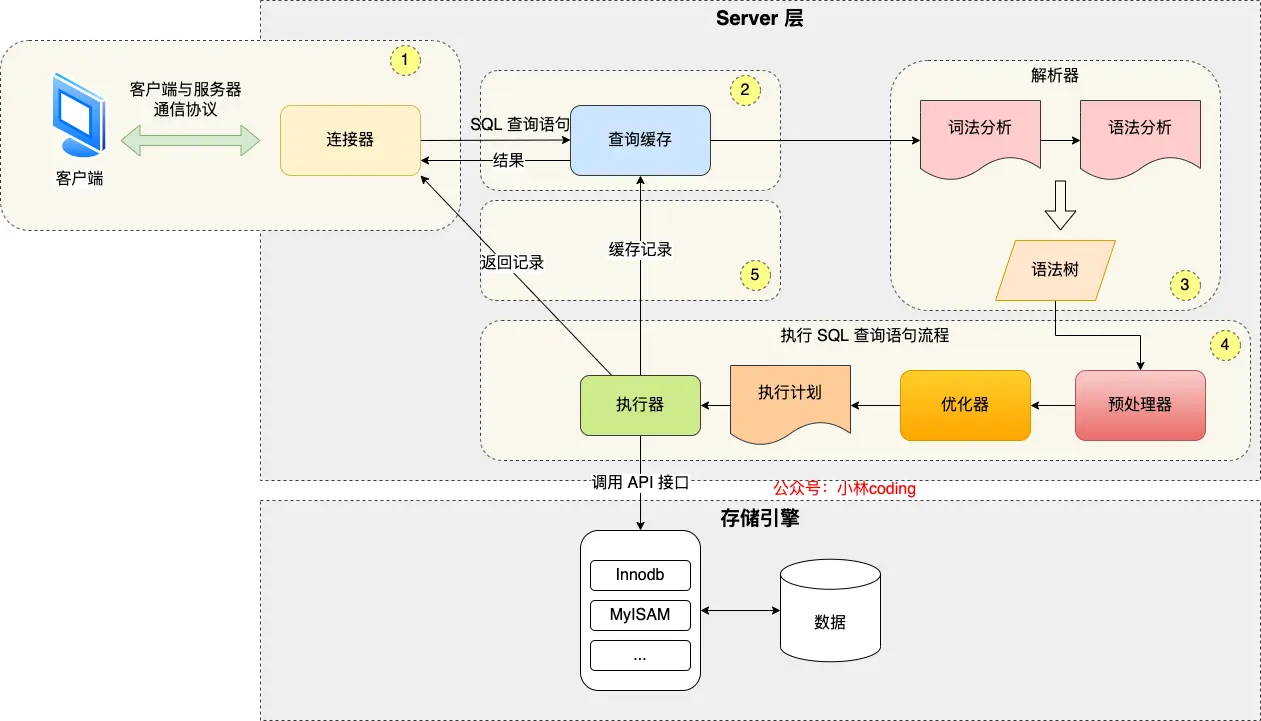
数据库查询执行流程
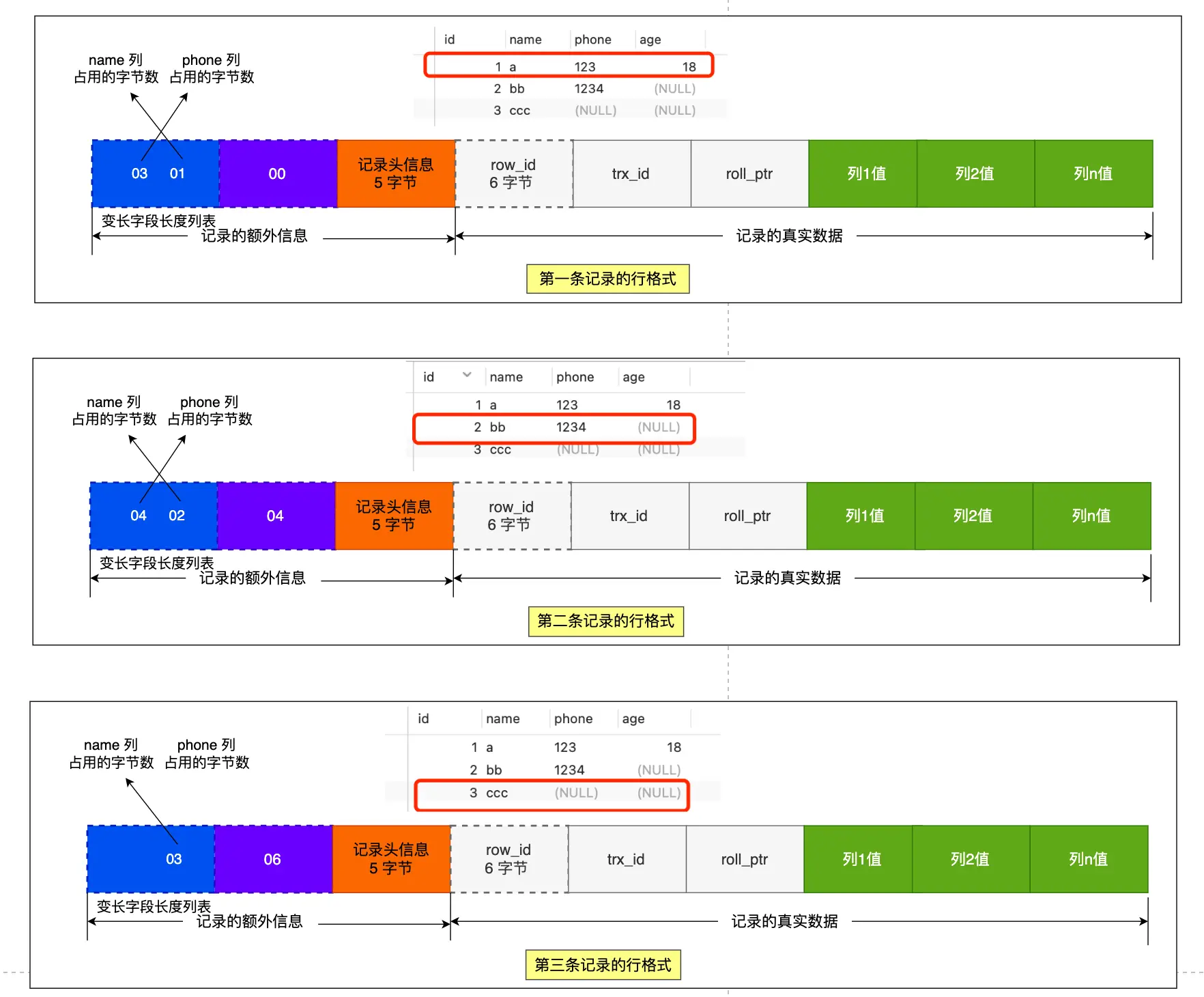
COMACT如何存储数据
行、页、区、段
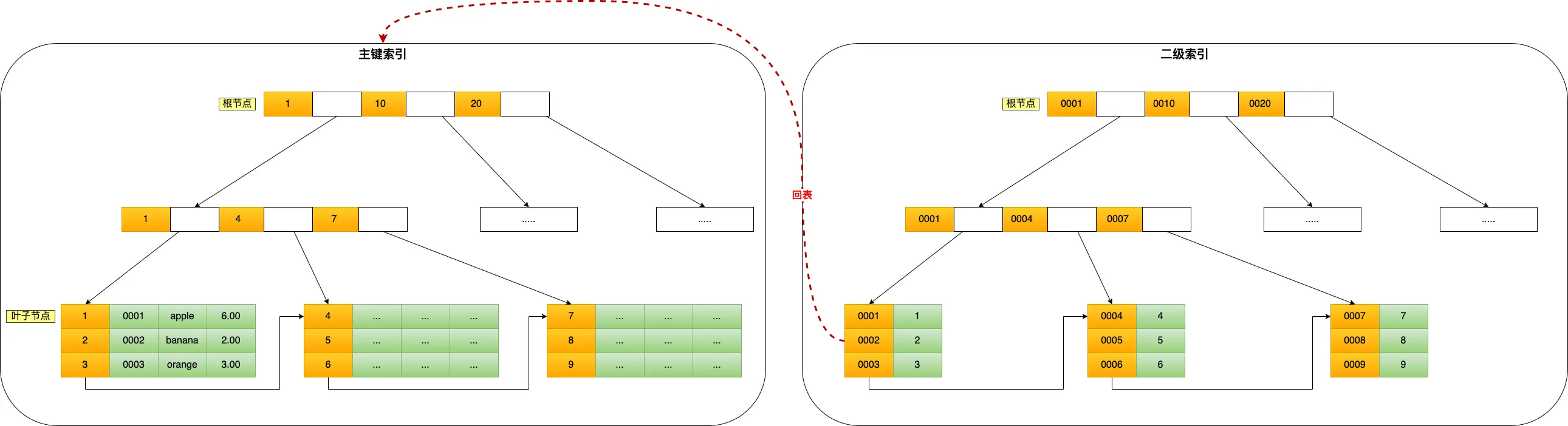
索引
普通索引
唯一索引:一个字段或多个字段或字段的组合值唯一
主键索引:主键上的
联合索引
使用联合索引时,存在最左匹配原则,需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的
顺序并不重要。**范围查询:**范围查询的字段可以用到联合索引,但是在范围查询字段的
后面的字段无法用到联合索引。(注意大于大于等于不一样,BETWEEN、like同理)建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
区分度就是某个字段 column 不同值的个数「除以」表的总行数联合索引进行排序(filesort)
select * from order where status = 1 order by create_time asc
分类:聚簇索引:索引上叶子节点是数据
分类:非聚簇索引:索引上叶子节点是索引,但有指向数据的块的指针
类型:
B+数索引全文索引哈希索引
从物理存储的角度来看,索引分为聚簇索引(主键索引)、二级索引(辅助索引)。二级索引如果查询的不是主键(或者联合索引的值),需要进行**回表**
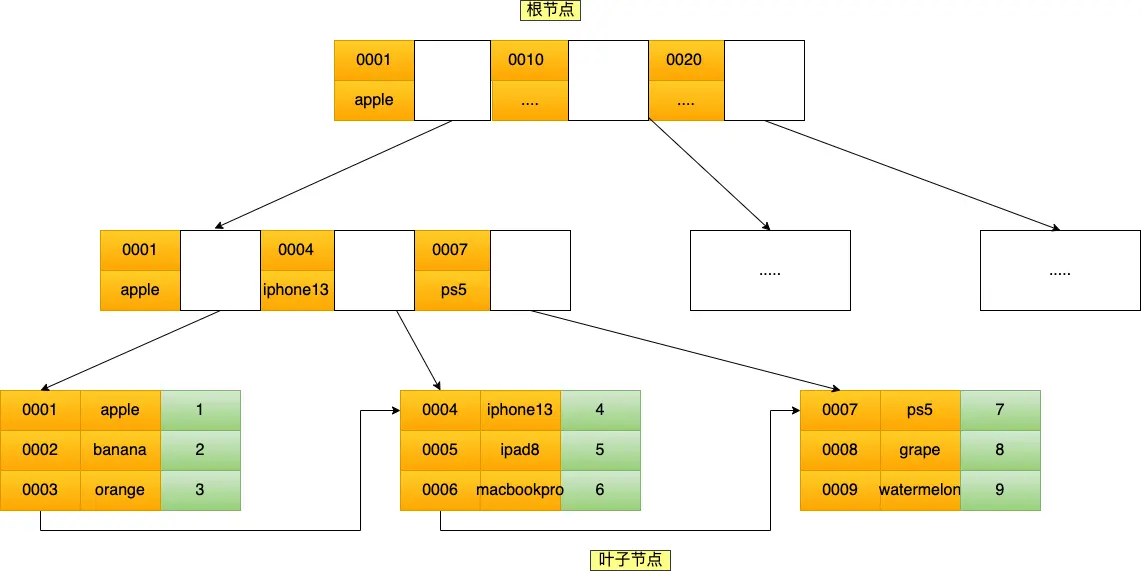
索引建立契机
适合:
字段有唯一性限制
经常用于
WHERE查询条件经常用于
GROUP BY和ORDER BY的字段
不适合:
WHERE条件,GROUP BY,ORDER BY里用不到的大量重复数据
表数据太少
经常更新的字段不用创建索引
索引优化
前缀索引优化:长字符串空间优化
覆盖索引优化:避免回表
主键索引最好是自增的:避免页分裂
尽量设置为NOT_NULL:方便优化器、
Null值列表占用空间防止索引失效
索引失效
使用!=或<>操作符:索引对期待扫描全部数据的查询通常没有帮助,尤其是不等式查询。
对索引列进行计算或函数操作
使用LIKE操作符
以%开头的模糊查询联合索引中没有使用最左前缀原则
数据类型不一致
如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列
B+树索引
相比于B树: 两者都是二叉查找树,B+索引没有数据,数据都在叶子节点上,叶子节点相连,B+树支持范围查找。时间复杂度为固定的log(n)
相比与Hash索引: Hash只在等值查找上比B+树好,其他都没B+好
推荐单表不超过2000w,是因为超过这个值,索引需要4层才能存储,需要消耗更多磁盘io
覆盖索引
用索引去覆盖要查找的数据范围,避免回表
count(*)与count(1)
效率:
count(*)=count(1)>count(id)>count(field)
优化count(*)
使用explain来获取估算值
另一个表保存统计值
数据库事务与ACID
作为一个逻辑工作单元进行执行的一系列操作,他可以满足四大条件
A原子性:要么全部完成,要么全部都不执行
C一致性:事务必须让数据库从一个一致性状态变为另一个一致性状态
I隔离性:提供一定的隔离级别,可以尽量减少外部并发操作的干扰
D持久性:事务提交后,对数据库的修改应该是永久的
隔离级别
并发可能带来的问题:
数据丢失、脏读、不可重复读、幻读
未提交读
已提交读:每次读取数据时成一个新的 Read View
可重复读:启动事务时生成一个 Read View
可序列化
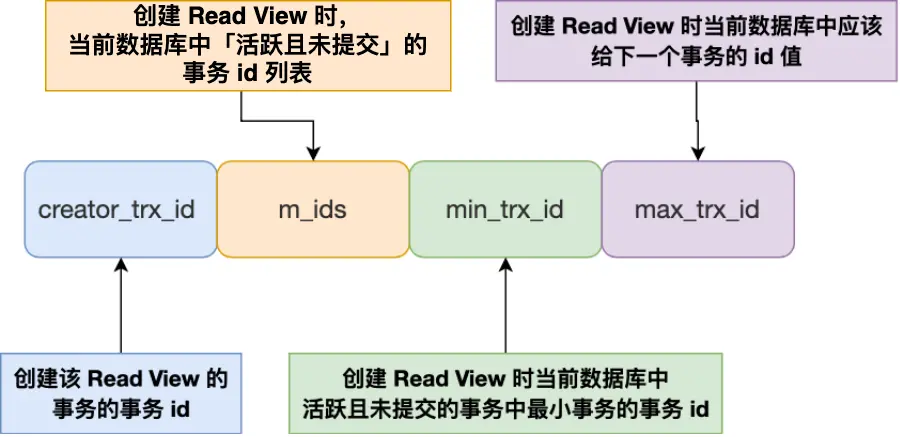
MVCC
需要先了解两个结构
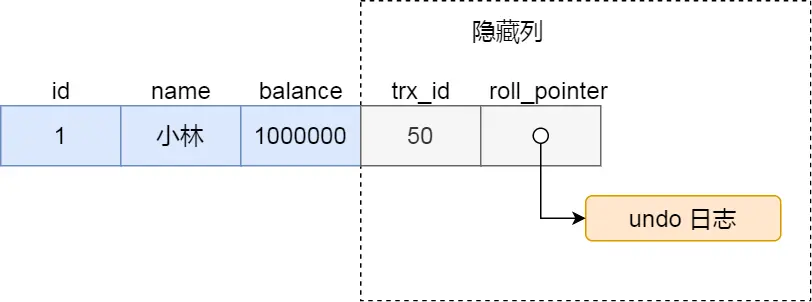
roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
MVCC流程(多版本并发控制)
事务在请求数据时,除了自己更新的记录可见以外,还有以下情况
如果记录的trx_id小于min_trx_id,代表之前已提交的事务的数据,所以
可见如果trx_id>max_trx_id,代表ReadView后启动的事务,所以
不可见如果在两者之间,则去判断是否在
m_ids中m_ids中代表事务活跃,所以
不可见不在m_ids中代表事务已提交,所以
可见
MySQL存储引擎
InnoDB:支持事务处理、行级锁定和外键约束,适合需要高并发写入和复杂数据关系的场景。它使用聚簇索引来提高数据访问速度。
MyISAM:不支持事务处理,但查询性能较高,适合只读或大量查询的应用。MyISAM使用非聚簇索引,且不支持外键。
性能优化
SQL语句优化,索引优化
分表、分库、分读写库
加入缓存
锁
分类
全局锁:数据库锁
表级锁
表锁
元数据锁MDL
意向锁:意向锁的目的是为了快速判断表里是否有记录被加锁
AUTO-INC锁:为了id自增
行级锁
记录锁:单条记录的锁
间隙锁:一个范围的锁
临键锁:记录锁+间隙锁组合,锁定范围以及记录本身
行级锁的SX分类
S共享锁:运行事务
读一行数据X排他锁:运行事务对数据进行
更新删除
如何加行级锁
加锁的对象是索引,加锁的基本单位是 next-key lock,其在一些场景下会退化成记录锁或间隙锁:在能使用记录锁或者间隙锁就能避免幻读现象的场景下会退化
唯一索引等值查询
加锁的对象是针对索引
记录存在的情况下加入记录锁
记录不存在的情况下加入间隙锁,锁到对应where的前后两个记录之间(因为锁是加到索引上的,所以必须要有值才能加锁)
唯一索引范围查询
加锁是否退化,依据是否有等于来判断,中间的都会是临建锁
多个值之间的范围都会分别加锁
非唯一索引等值查询
加入锁的时候,除了要判断非唯一索引以外,还要判断主键索引是否在锁范围内
对于数据存在的情况,除了会锁定
(x-1,x]以外,还会锁定(x, x+y)其中x+y为下一条记录(这是因为二级索引插入数据的时候,可能插入(x,id+1)这种x值,但是id更大的。所以需要判断x和id)
非唯一索引范围查询
为二级索引加入的都是临建锁。不存在退化现象
对于包含了末尾的,会有
supremum pseudo-record作为末尾,也就是(x, +inf)
没有索引的查询
锁住索引全范围的,但是注意不是表锁使用
sql_safe_updates来避免某些update语句运行成功,这样能初期发现问题如果优化器最后选择了全表查询,可以用
force index([index_name])强行用索引进行更新
死锁了怎么解决
设置事务等待锁的超时时间
开启主动死锁检测
other
间隙锁的意义只在于阻止区间被插入,因此是可以共存的遇到唯一键冲突后会给记录加上S锁:
id-记录锁x-临键锁
日志
undoLog
回滚日志实现了事务中的原子性,主要用于事务回滚和 MVCC。
redoLog
重做日志实现了事务中的持久性,主要用于掉电等故障恢复;
binLog
归档日志Server 层生成的日志,主要用于数据备份和主从复制;
外键
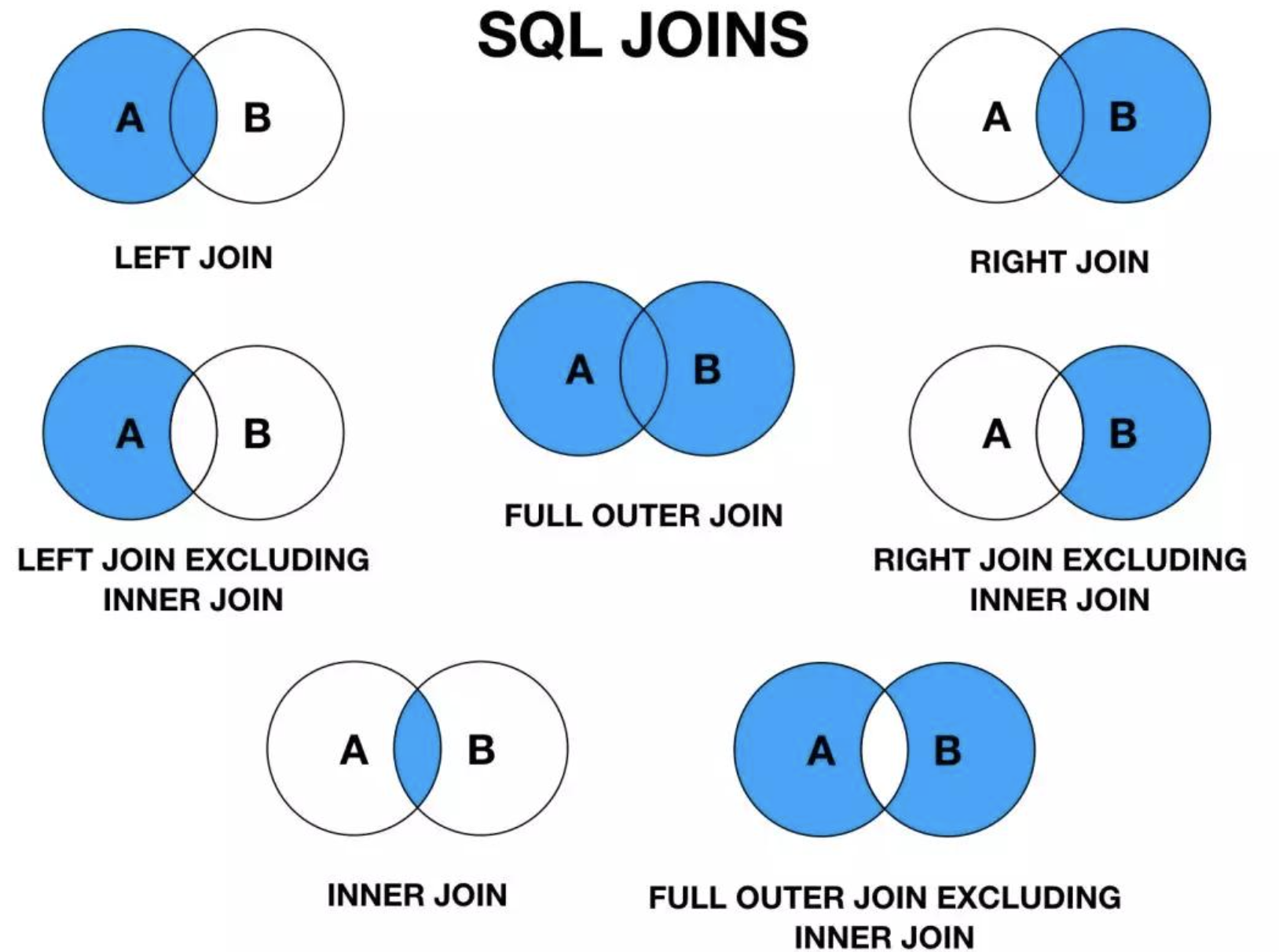
LEFT JOININNER JOINRIGHT JOINFULL OUTER JOIN
Coding
创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
-- 创建数据库
CREATE DATABASE example_db;
-- 使用数据库
USE example_db;
-- 创建表
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 修改表(添加列)
ALTER TABLE users ADD COLUMN status VARCHAR(10) DEFAULT 'active';
-- 删除列
ALTER TABLE users DROP COLUMN status;
-- 删除表
DROP TABLE IF EXISTS users;
-- 删除数据库
DROP DATABASE IF EXISTS example_db;
CURD
1
2
3
4
5
6
7
8
9
10
11
12
-- 插入数据
INSERT INTO users (username, email) VALUES ('johndoe', 'john@example.com');
-- 查询数据
SELECT * FROM users;
SELECT username, email FROM users WHERE id > 5 ORDER BY created_at DESC LIMIT 10;
-- 更新数据
UPDATE users SET email = 'john.doe@example.com' WHERE id = 1;
-- 删除数据
DELETE FROM users WHERE id = 1;
高级查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- 聚合查询
SELECT COUNT(*) AS total_users FROM users;
SELECT MAX(created_at) AS last_signup FROM users;
-- 分组与聚合
SELECT status, COUNT(*) AS users_count FROM users GROUP BY status HAVING users_count > 1;
-- 连接查询
SELECT u.username, o.order_date FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.total > 100;
-- 子查询
SELECT username FROM users WHERE id IN (SELECT user_id FROM orders WHERE total > 500);
索引和性能优化
1
2
3
4
5
6
7
8
-- 创建索引
CREATE INDEX idx_username ON users (username);
-- 删除索引
DROP INDEX idx_username ON users;
-- EXPLAIN 来分析查询性能
EXPLAIN SELECT * FROM users WHERE username = 'johndoe';