ROME论文解读:借ROCK与ROLL构建Agent由来的笔记
最近阿里巴巴新出了一篇论文:《Let It Flow: Agentic Crafting on Rock and Roll》
1
我研读了几天,字里行间看到的都是我的新框架的东西,想一想自己还在做设计和开发,别人都已经发论文了,心里略感悲凉。本文做一些阅读笔记和总结。
前言
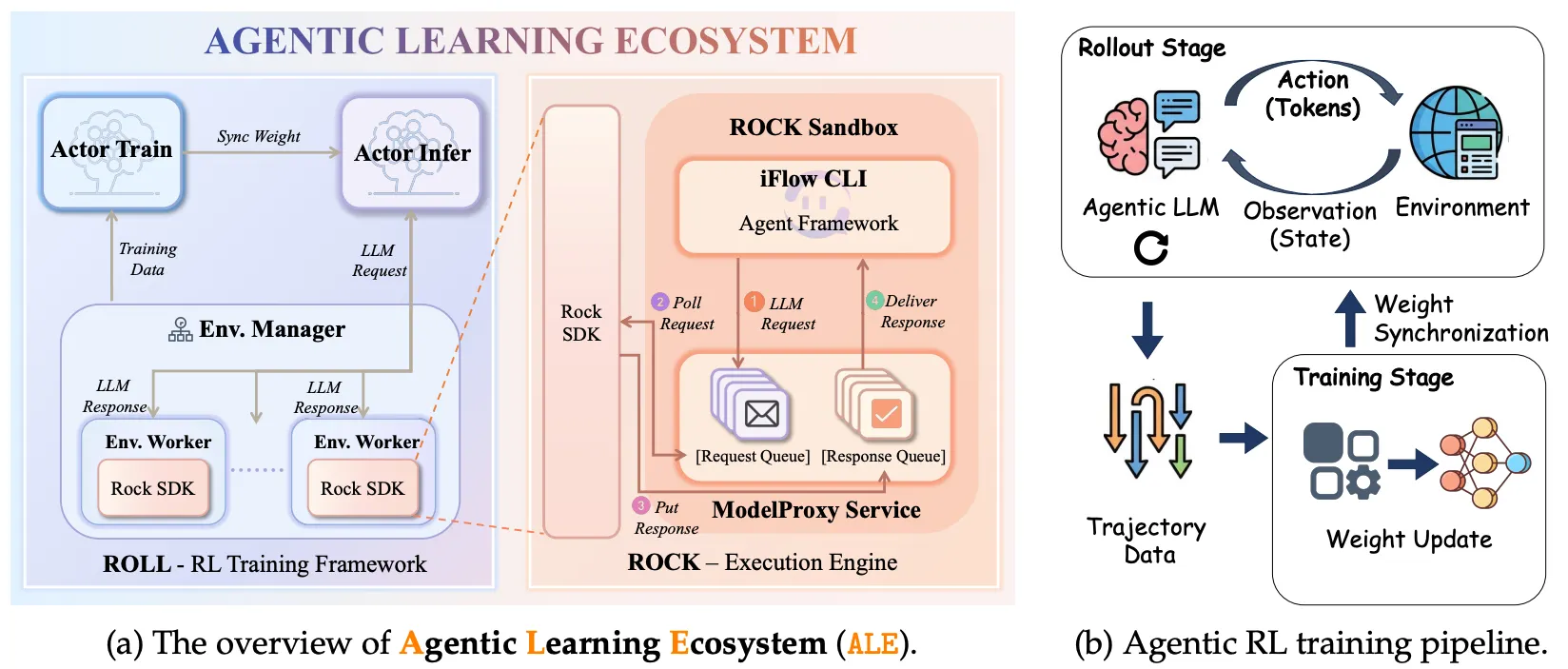
这篇论文提出了一个名为 ALE (Agentic Learning Ecosystem) 的全栈生态系统。最有意思的是它的 infra 部分,如果不搞大规模 Agent 训练可能很难体会其中的痛点。整个生态包含三个部分:
ROLL:负责 RL 训练的框架(重点看这个)。
ROCK:负责环境执行的沙盒引擎。
iFlow CLI:Agent 框架,负责上下文管理。
重点聊聊 ROLL。作为一个正在搞类似系统的工程师,看完他们的设计,确实感觉搔到了痒处。我做的设计路线可以参考博客:《Architectural Evolution: 强化学习系统》
ALE架构:
ROLL:大规模 Agentic RL 的解法
对于做 RL 基础设施的人来说,Agent 场景下的 RL 和传统的文本 RL(如 RLHF)有很大不同,最大的区别在于 Rollout 阶段极慢且方差极大。一个 Agent 任务可能要交互很多轮,环境返回也很慢。
ROLL 采用的是 Train 与 Infra 异构分离的架构,这种思路现在比较主流,但细节上的优化才是见真章的地方。以下这几点是我觉得比较精髓的:
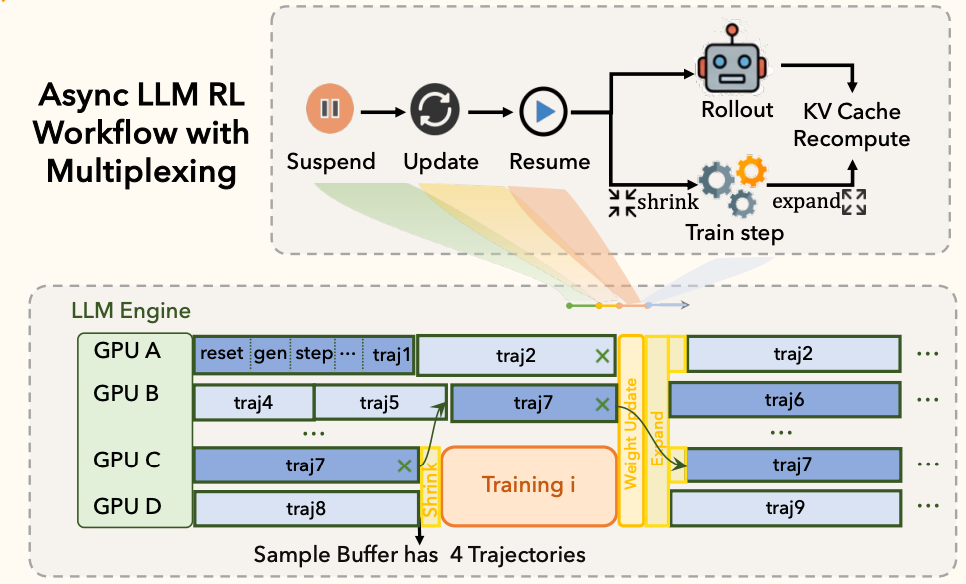
1. Train-Rollout 多路复用 (Time-Division Multiplexing)
这是我觉得最亮眼的一个设计。
痛点:在 Agent 训练中,Rollout 阶段通常有极其明显的长尾效应(Long-tail Latency)。
只有少量样本(Stragglers)会跑到最大 Context 长度,或者卡在复杂的环境交互里。
为了这一小撮慢样本,大部分 Rollout GPU 其实是在空转(Valley 阶段)等待的。
而 Train 阶段又是短暂且爆发式的,算完梯度就没事干了。如果按照常规做法静态划分 GPU 资源(比如 80% 做 Rollout,20% 做 Train),两边都会出现巨大的资源泡沫(Bubbles)。
解法:ROLL 基于”时分复用”的思路搞了个动态资源池。
Shrink 操作:当 Sample Buffer 攒够了要训练的数据,系统利用 Rollout 处于”低谷”(大部分样本生成完了,只剩长尾在跑)的时机,迅速把空闲下来的 GPU 划拨给 Train 节点。
Expand 操作:Train 完后,立刻把资源还给 Rollout 去跑下一轮并发。这种设计巧妙地利用了 Agent 任务特有的”脉冲式训练”和”长尾式生成”的互补特性,把利用率榨得很干。
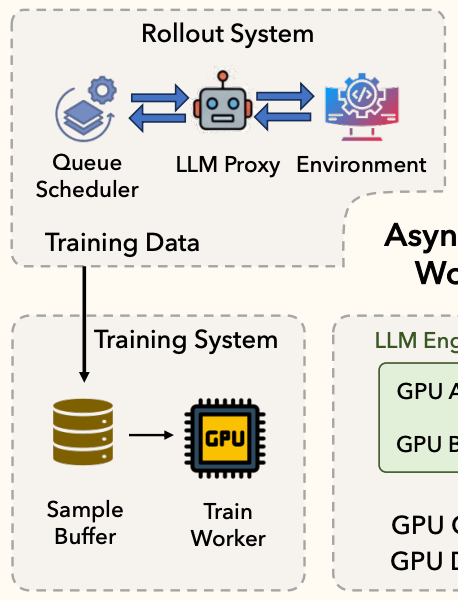
2. 角色抽象与单控制器 (Role Abstraction & Single-Controller)
痛点:以前写 RL 框架,最烦的就是各种 Worker 挂掉或者状态同步。Agent 训练步骤又特别碎(推理、环境、奖励、更新),把所有逻辑塞在一个大 Worker 里很难维护,也很难针对性扩容。
解法:ROLL 采用了类似 Kubernetes 控制平面的逻辑。
它引入了一个 Cluster Abstraction 和 Single-Controller 编程模型。开发者只需要对着 Controller 编程,底层的异构 Worker 调度由框架搞定。
角色拆解:
LLM Inference Worker:只管模型生成,专注吞吐。
Environment Worker:只管跟 ROCK 沙盒交互,IO 密集型。
Reward Worker:只管算分。
Training Worker:只管反向传播。
这种解耦的好处是显而易见的:环境太慢?单独加 Environment Worker 就行,不用动推理节点。对于 Infra 团队来说,这种”微服务化”的 RL 框架维护成本低很多。
3. Rollout 细粒化流水线 (Fine-grained Rollout)
痛点:论文里提到,环境交互(Environment Interaction)在 Agent 训练中占比能到 15% 以上。传统的做法是 Batch 级别的串行:生成 Batch -> 执行 Batch -> 算分 Batch。在 Agent 场景下,只要有一个环境卡住,整个 Batch 都在等。
解法:ROLL 把 Rollout 阶段内部也做了 Pipeline,而且粒度细到了 Sample 级别。
LLM 生成、环境交互、奖励计算 这三个阶段是流水线并发的。
只要 GPU 有空,就开始算下一个 token 或者处理下一个请求,绝不让 LLM 等环境。这其实是在用计算的 Pipeline 掩盖环境的 IO 延迟,非常典型的高并发系统设计思路。
4. 异步训练与策略控制 (Asynchronous Training with Staleness Control)
痛点:完全同步训练太慢(GPU 等数据),完全异步又会导致 Off-policy 问题严重(模型更新了,数据还是旧模型跑出来的),这在长程 Agent 任务里会导致训练不收敛。
解法:ROLL 在经典的 Producer-Consumer 模式上加了个保险。
维护一个 Asynchronous Ratio(异步比率)。
这个比率控制了”当前训练策略版本”和”样本生成时的策略版本”的最大差值。
如果 Buffer 里的数据太老(Policy Lag 过大),系统会直接扔掉,而不是强行拿来训练。这既保证了 GPU 不空转,又守住了算法收敛的底线。
5. Agent-Native 的原语支持 (Chunk-Level & State-Aware)
这一点容易被忽略,但我觉得是它区别于传统 RLHF 框架(比如只做 PPO 的框架)的根本,也是新一代Agentic训练与传统LLM-RL训练的最大区别。
痛点:传统的 LLM RL 框架依然是 Token 粒度的。但在 Agent 任务里,很多时候我们需要的是”思考-行动-观察”这样一个完整的交互闭环(Chunk)。而且长程任务(Long-horizon)如果每次都从头跑,效率太低,很难探索深层状态。
解法:ROLL 原生支持 Chunk-Level 的操作。
Chunk-aware Credit Assignment:它支持以 Chunk 为单位进行信用分配,专门为论文里的 IPA(Interaction-Perceptive Agentic Policy Optimization)算法铺路,解决了长程对应的稀疏奖励难题。
Initialized Sampling(读档重开):结合 ROCK 的能力,ROLL 支持从轨迹的中间状态开始采样(基于快照)。这意味着模型可以反复尝试任务中后段的难点,而不用每次都从
Hello World开始跑。这对长程任务的样本效率简直是降维打击。
其他值得关注的点
除了 ROLL,另外两个组件也有不少工程亮点:
ROCK (环境执行引擎)
它解决了一个RL训练时候的常见问题:大规模并发环境的隔离与调度。
它通过 GEM API 标准化了环境接口,意味着无论是不是他们内部的 Agent,只要符合标准都能跑。
还有一个 EnvHub 的设计,专门加速环境冷启动,这对于动不动就重置环境的 RL 来说太重要了。
iFlow CLI (上下文管理)
论文提到了一个 Agent Native Mode。这是为了解决 Train/Serving 不一致的问题:训练框架(ROLL)不需要重复实现复杂的 Agent 逻辑(如 Prompt 拼接、工具调用),而是通过 Proxy 直接复用 iFlow CLI 的逻辑。
这点非常务实,做过落地的人都知道,如果训练代码和线上业务代码有两套 Context 管理逻辑,效果对齐简直是噩梦。